资源介绍
使用 Python、Streamlit 与机器学习构建糖尿病数据分析仪表盘(中文字幕英文视频教程)
在当今数据驱动决策的时代,医疗健康领域对数据处理与分析的需求日益增长,糖尿病作为常见的慢性疾病,其相关数据的有效分析对病情监测、风险预测具有重要意义。本课程聚焦糖尿病数据领域,以 “理论 + 实践” 的模式,带领学习者从零开始掌握使用 Python、Streamlit 工具以及机器学习技术,最终完成一个功能完善的糖尿病数据分析仪表盘的开发。
课程整体结构清晰,共分为 5 个核心模块,涵盖从基础环境搭建到高级机器学习模型应用与项目部署的全流程。通过视频教学、配套文档与实操案例相结合的方式,确保不同基础的学习者都能逐步掌握相关技能。经统计,课程包含的视频总个数为 31 个,每个视频均配有中文字幕,同时搭配多个辅助学习的 HTML 文档,为学习者提供全方位的学习支持。
二、课程模块详情
(一)模块 1:课程入门与环境准备(Introduction)
本模块作为课程的开篇,旨在帮助学习者快速了解课程目标、完成学习环境搭建,并熟悉课程所需的数据集与基础工具,为后续学习奠定基础。
课程目标介绍:通过 1 个视频(“1 - Introduction - What we'll create in this course!”),清晰阐述本课程最终要完成的糖尿病数据分析仪表盘的核心功能、应用场景与学习价值,让学习者明确学习方向。
环境搭建指导:包含 1 个视频(“2 - Anaconda Download Instructions”),详细讲解 Anaconda 的下载与安装步骤。Anaconda 作为数据科学领域常用的环境管理工具,能帮助学习者便捷地配置 Python 运行环境,避免因环境配置问题影响学习进度。
Jupyter 工具实操:配备 2 个视频(“3 - Opening the Files in Jupyter”)与 1 个辅助 HTML 文档(“3 - Download Link for Jupyter Files.html”)。视频演示如何在 Jupyter 中打开课程提供的文件,HTML 文档则提供 Jupyter 文件的下载链接,同时帮助学习者熟悉 Jupyter 的基本操作,为后续代码编写做好准备。
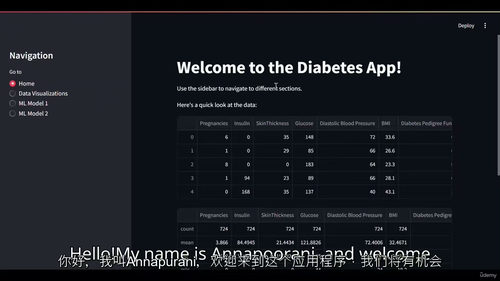
基础补充与数据集解析:包含 1 个视频(“4 - Explanation of the Dataset”)与 1 个 Python 基础 HTML 文档(“4 - Python Crash Course.html”)。视频详细解读课程所用糖尿病数据集的结构、字段含义与数据特点,让学习者了解数据背景;HTML 文档则针对 Python 基础薄弱的学习者,提供快速入门知识,涵盖数据类型、语法规则等核心内容,确保学习者具备后续编码所需的基础能力。
本模块共包含 4 个视频,通过循序渐进的内容设计,帮助学习者快速进入学习状态,完成从 “了解课程” 到 “具备基础操作能力” 的过渡。
(二)模块 2:基础数据洞察提取(Extracting Basic Insights)
在完成环境准备与基础认知后,本模块聚焦于糖尿病数据的基础分析,教授学习者如何通过编写基础代码提取数据中的关键信息,并将分析结果初步集成到应用中。
基础代码编写:通过 1 个视频(“1 - Coding Basic Commands”),演示如何使用 Python 编写基础的数据处理代码,包括数据读取、数据筛选、基本统计量计算等操作,帮助学习者掌握从数据中提取基础洞察的方法,例如计算糖尿病患者的年龄分布均值、血糖指标范围等关键信息。
应用集成实操:分为 2 个视频(“2 - Uploading Basic Commands to App - Part 1”“3 - Uploading Basic Commands to App - Part 2”),分步骤讲解如何将编写好的基础数据处理代码上传并集成到 Streamlit 应用中。Streamlit 作为轻量级的 Web 应用开发工具,能让学习者快速将数据分析成果转化为可交互的 Web 页面,本部分内容帮助学习者打通 “代码编写” 到 “应用呈现” 的关键环节。
本模块共包含 3 个视频,通过实操性极强的内容,让学习者掌握数据洞察提取的核心技能,同时初步接触应用开发,建立 “数据 - 代码 - 应用” 的完整认知。
(三)模块 3:数据可视化(Data Visualization)
数据可视化是呈现数据规律、传递数据价值的重要手段。本模块围绕糖尿病数据的可视化展开,教授多种可视化图表的制作方法,并实现可视化功能与 Web 应用的集成,同时补充数据清洗知识,确保数据质量。
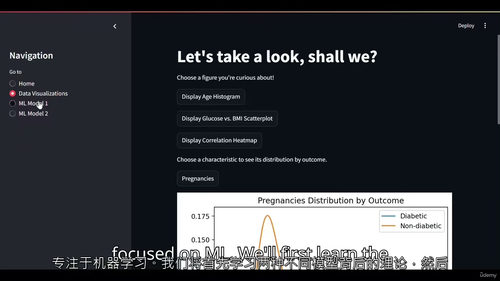
可视化理论与基础图表制作:包含 1 个辅助 HTML 文档(“1 - Why Visualize Data.html”)与 1 个视频(“1 - Histograms and KDEs”)。HTML 文档阐述数据可视化的重要性、适用场景与核心原则;视频则详细演示如何使用 Python 相关库(如 Matplotlib、Seaborn)制作直方图(Histograms)与核密度估计图(KDEs),通过这两种图表呈现糖尿病数据中关键指标的分布特征,例如患者血糖水平的分布情况。
可视化功能集成:配备 2 个视频(“2 - Adding Histograms to Webapp”“3 - Adding KDEs to Webapp”),讲解如何将制作好的直方图与核密度估计图集成到 Streamlit 应用中,实现图表的交互式展示,让用户能够通过应用直观查看数据分布规律。
多样化图表学习:包含 3 个视频(“4 - Scatterplots”“5 - Subplots”“6 - Heatmaps and Correlations”),分别介绍散点图、子图与热力图的制作方法。散点图可用于分析两个变量(如血糖与血压)之间的相关性;子图能实现多图表的组合展示,提升数据呈现的丰富性;热力图则可清晰呈现多个变量间的相关系数,帮助挖掘糖尿病数据中隐藏的关联关系。
数据清洗与综合集成:包含 2 个视频(“7 - Data Cleaning”“8 - Adding Scatterplots, Correlation Heatmap, and Cleaned Data to App”)。数据清洗视频讲解如何处理糖尿病数据中的缺失值、异常值等问题,确保数据质量;综合集成视频则演示将散点图、相关性热力图以及清洗后的数据集统一集成到 Web 应用中,实现可视化功能的全面升级,让应用具备更完善的数据展示能力。
本模块共包含 8 个视频,通过丰富的图表类型教学与应用集成实操,让学习者熟练掌握数据可视化的核心技能,提升数据呈现与解读能力。
(四)模块 4:机器学习 - 逻辑回归与决策树分类器(Machine Learning - Logistic Regression & Decision Tree Classifiers)
机器学习是实现数据预测与分析的核心技术,本模块聚焦糖尿病风险预测场景,教授两种经典的分类算法 —— 逻辑回归与决策树,并实现算法在 Jupyter 中的验证与 Streamlit 应用中的集成,同时补充机器学习基础理论与 Python 进阶知识。
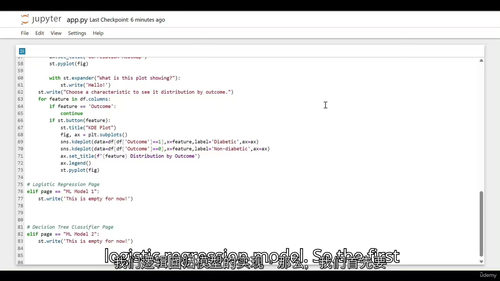
逻辑回归学习:包含 3 个视频(“1 - Logistic Regression Theory”“2 - Logistic Regression in Jupyter”“3 - Extra! In-Depth, Explained Logistic Regression in Jupyter”)与 1 个辅助 HTML 文档(“5 - Dictionaries Crash Course - Skip if familiar with Python dictionaries.html”)。理论视频讲解逻辑回归的基本原理、适用场景与数学模型,帮助学习者建立理论认知;Jupyter 实操视频分基础版与深入版,详细演示如何在 Jupyter 环境中使用 Python 实现逻辑回归模型,对糖尿病数据进行风险预测,深入版视频还针对模型参数调优、结果分析等内容展开更细致的讲解;HTML 文档则针对 Python 字典知识进行补充,为学习者理解模型代码中的数据存储与处理逻辑提供支持。
模型评估与应用集成:包含 2 个视频(“4 - Explanation of Metrics”“5 - Logistic Regression in Streamlit”)。模型评估视频讲解准确率、精确率、召回率等常用的分类模型评估指标,帮助学习者正确判断逻辑回归模型的预测效果;应用集成视频则演示如何将逻辑回归模型部署到 Streamlit 应用中,实现用户通过输入相关健康指标,即可获取糖尿病风险预测结果的功能。
决策树分类器学习:包含 1 个辅助 HTML 文档(“6 - Supervised vs. Unsupervised Learning.html”)与 3 个视频(“6 - Decision Tree Classifier Theory”“7 - Decision Trees in Jupyter”“8 - Decision Trees in Streamlit”)。HTML 文档介绍监督学习与无监督学习的核心区别,为决策树算法的学习奠定理论基础;理论视频讲解决策树分类器的原理、结构与优缺点;Jupyter 实操视频演示如何在 Jupyter 中构建决策树模型,并基于糖尿病数据进行训练与验证;应用集成视频则将决策树模型集成到 Streamlit 应用中,与逻辑回归模型形成互补,让用户可选择不同模型进行风险预测,提升应用的实用性。
本模块共包含 10 个视频,通过 “理论 - 实操 - 集成” 的完整流程,让学习者掌握两种核心机器学习算法的应用,具备基于数据构建预测模型并集成到应用中的能力。
(五)模块 5:额外内容 - 过拟合与应用部署(Extra Overfitting & Deploying the App)
本模块作为课程的补充与拓展,围绕机器学习模型优化与项目最终部署展开,帮助学习者解决模型常见问题,实现项目从 “本地开发” 到 “在线可用” 的跨越。
过拟合问题解析:包含 1 个辅助 HTML 文档(“1 - Extra ML Lecture What is overfitting.html”),详细讲解过拟合的概念、产生原因与解决方法。过拟合是机器学习模型训练中常见的问题,会导致模型在训练数据上表现良好,但在新数据上预测效果差,文档内容帮助学习者识别并规避过拟合问题,提升模型的泛化能力。