

资源介绍
幕英文视频教程)
一、商业智能导论:把握数据驱动决策的演进脉络
课程的第一模块聚焦于商业智能的基础理论与发展历程,为学习者构建完整的知识框架。
在《商业智能的演进》章节中,我们将追溯 BI 从早期的报表系统到现代智能分析平台的发展轨迹。学习者将了解到,商业智能的演进始终与技术革新紧密相连 —— 从数据库技术的成熟推动了数据仓库的诞生,到机器学习算法的突破赋能了预测分析,每一次技术飞跃都为 BI 注入了新的活力。通过梳理这一过程,学习者能够深刻理解 BI 的核心价值:将数据转化为可执行的商业洞察,而非简单的数据分析工具堆砌。
《商业智能价值链》则系统解析了 BI 工作的全流程:从业务需求定义开始,历经数据采集、处理、分析、可视化到决策应用的完整闭环。这一章节将帮助学习者建立 “以业务目标为导向” 的分析思维,理解每个环节在价值链中的作用 —— 例如,数据采集阶段需确保数据源的可靠性与相关性,分析阶段则要选择与业务问题匹配的方法,而可视化阶段的核心是让非技术人员快速理解数据背后的含义。
《商业智能的应用场景》通过制造业、零售业、金融业等多行业案例,展示 BI 在实际业务中的价值。比如,零售企业可通过 BI 分析客户消费行为,优化商品陈列与促销策略;金融机构借助 BI 实时监控风险指标,提升风控效率。这些案例将理论与实践相结合,让学习者直观感受 BI 如何解决真实业务痛点。
二、商业数据预处理:打造高质量的分析基石
数据预处理是数据分析的 “地基工程”,直接决定后续建模的准确性与可靠性。本模块将深入讲解数据预处理的核心技术,并通过实战训练提升学习者的操作能力。
《商业数据预处理》章节系统介绍了数据预处理的原则与方法。学习者将掌握数据类型转换、缺失值处理、异常值识别等关键技能 —— 例如,对于缺失率较高的变量,需评估其对分析目标的影响,再决定采用删除、填充或建模预测等处理方式;而异常值的处理则需结合业务背景,区分数据错误与真实的极端值。这一章节强调 “数据质量决定分析质量” 的理念,培养学习者严谨的数据处理态度。
《探索性数据分析(EDA)》是数据预处理阶段的重要环节。通过统计描述、分布分析、相关性分析等方法,学习者将学会初步探索数据特征,发现潜在的规律与问题。例如,通过绘制直方图观察变量分布形态,判断是否符合建模假设;通过计算相关系数,识别变量间的多重共线性。这些探索性工作能为后续建模提供重要指引,避免盲目套用算法。
本模块的两个实战章节 ——《探索性数据分析实战》与《数据清洗实战》,将让学习者在 R 语言环境中动手实践。通过处理真实的商业数据集(如客户交易数据、产品销售数据),学习者将熟练运用dplyr、tidyr等 R 包进行数据清洗与转换,掌握ggplot2的基础绘图功能实现 EDA 可视化。实战训练强调 “边做边学”,帮助学习者快速掌握代码编写技巧,同时理解每个操作背后的业务逻辑。
三、有监督数据建模:预测未知,驱动精准决策
有监督学习是商业预测的核心技术,本模块将聚焦于线性回归与分类算法,培养学习者的预测分析能力。
《线性回归》章节从基础的一元线性回归入手,逐步深入到多元线性回归、多项式回归等复杂模型。学习者将掌握回归模型的假设检验(如正态性检验、异方差检验)、变量选择方法(如逐步回归、LASSO 正则化),以及如何解读回归系数的经济含义。例如,在销售额预测模型中,回归系数可量化广告投入、促销活动等因素对销售额的影响程度,为资源分配提供数据支持。
《分类算法》则涵盖逻辑回归、决策树、随机森林等常用分类模型。通过对比不同算法的原理与适用场景,学习者将学会根据业务问题选择合适的模型 —— 例如,信用卡欺诈检测需优先考虑模型的召回率,而客户流失预测则需平衡精确率与覆盖率。章节还将介绍模型评估指标(如混淆矩阵、ROC 曲线),帮助学习者科学判断模型性能。
《线性回归实战》与《分类实战》将引导学习者使用 R 语言实现完整的建模流程:从数据拆分(训练集与测试集)、模型训练、参数调优到结果验证。通过实战,学习者将深刻理解 “模型不是越复杂越好”,而是要在解释性与预测力之间找到平衡,例如,在客户价值预测中,简单的线性回归可能比黑箱模型更易被业务部门接受。
四、无监督数据建模:发现数据中的隐藏结构
无监督学习无需依赖标签数据,擅长发现数据中的潜在模式,本模块将重点讲解聚类与时间序列分析技术。
《聚类分析》章节介绍 K - 均值聚类、层次聚类等算法的原理与应用。学习者将掌握如何根据数据特征选择聚类数目(如通过肘部法、轮廓系数),以及如何解读聚类结果的业务含义。例如,在客户分群中,聚类分析可将客户划分为高价值忠诚客户、潜力增长客户等群体,为精细化营销提供依据。章节还将探讨聚类结果的可视化方法,如使用主成分分析(PCA)降维后绘制聚类散点图。
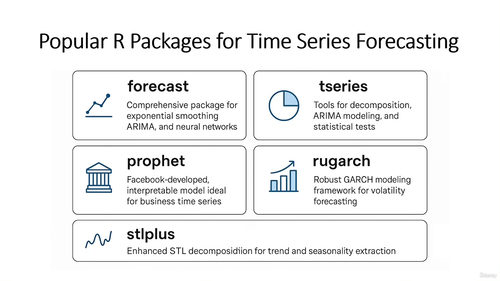
《时间序列分析》聚焦于带时间属性的数据建模,涵盖平稳性检验、ARIMA 模型、指数平滑等技术。通过学习,学习者将掌握如何处理季节性数据(如月度销售额中的节日效应)、预测未来趋势(如季度营收预测)。章节强调时间序列的 “序列相关性” 特征,引导学习者避免将时间序列误认为独立样本而导致的建模错误。
两个实战章节将让学习者在 R 语言中实践聚类与时间序列分析。例如,使用kmeans函数对产品销售数据进行聚类,识别不同的销售模式;利用forecast包对股票价格或网站流量进行时间序列预测。实战中,学习者将体会到无监督学习的灵活性 —— 无需预设标签即可发现新的业务洞察,但也需警惕过度解读聚类结果的风险。
五、数据可视化:让数据故事更具说服力
数据可视化是连接分析结果与业务决策的桥梁,本模块将教授如何使用 R 语言创建专业、直观的可视化作品。
《GGPlot》章节系统讲解 ggplot2 包的语法逻辑与绘图技巧。学习者将掌握从基础散点图、柱状图到复杂热图、生存曲线的绘制方法,理解 “图层叠加” 的设计理念 —— 通过数据层、美学映射层、几何对象层、统计变换层的组合,构建兼具美感与信息量的图表。章节特别强调可视化的 “受众导向” 原则:面向高管的汇报需简洁突出结论,而供分析师使用的图表则需包含更多细节。
《地理可视化》则聚焦于空间数据的呈现,介绍如何使用 R 语言绘制热力图、 choropleth 地图(区域着色图)等。例如,通过地理可视化展示不同地区的销售业绩分布,直观发现市场空白区域;或绘制客户分布热力图,优化线下门店选址。章节将讲解空间数据处理的特殊技巧,如坐标转换、地图投影选择等。
《GGPlot 实战》与《地理可视化实战》将通过真实业务场景(如年度销售报告、市场分析 dashboard),训练学习者的可视化实战能力。学习者将学会根据数据类型与分析目标选择合适的图表类型 —— 例如,展示趋势用折线图,比较类别用箱线图,分析分布用直方图 —— 并通过颜色、标签、注释的优化,让图表 “自说明” 数据故事。
课程总结:从工具到思维的全面提升
本课程通过五个模块的系统学习,将帮助学习者实现从 “数据新手” 到 “分析能手” 的转变。无论是商业智能的理论框架、数据预处理的核心技能,还是有监督 / 无监督建模的实战方法,亦或是数据可视化的呈现技巧,每个环节都紧密围绕 “解决实际业务问题” 展开。
通过 R 语言这一工具的系统训练,学习者不仅能掌握代码编写能力,更能培养 “数据驱动决策” 的思维方式 —— 学会用数据验证假设,而非依赖经验判断;用科学方法分析问题,而非凭直觉下结论。这些能力将为学习者在市场营销、运营管理、金融风控等诸多领域的职业发展赋能,使其成为企业不可或缺的数据分析人才。
无论是希望转型数据分析的职场人,还是计划进入商业智能领域的学生,本课程都将为你打开数据世界的大门,让你在数字经济的浪潮中把握机遇,创造价值。