
资源介绍
在数字化业务高速发展的当下,系统稳定性与服务质量已成为保障业务连续性的核心支柱,而站点可靠性工程(SRE)正是实现这一目标的关键方法论。本课程《SRE:概念与实践》(SRE - Concepts and Principles)围绕 SRE 核心知识体系展开,通过 5 大模块、29 个视频课程(注:经统计 MP4 文件共 29 个,无 MKV 文件)与配套中文字幕(SRT 格式),从基础认知到实战应用,全方位拆解 SRE 的工作逻辑、核心工具与落地方法,帮助学习者掌握保障系统稳定、提升服务可靠性的关键能力,适用于运维工程师、开发工程师、技术管理者等所有关注系统可靠性的技术从业者。
一、探究问题本质:SRE 的日常与核心差异
课程第一模块 “探究问题:SRE 的值班日常”(Investigating Issues - On-call with an SRE)共包含 7 个视频,聚焦 SRE 的基础认知与日常工作场景,帮助学习者建立对 SRE 的初步理解。
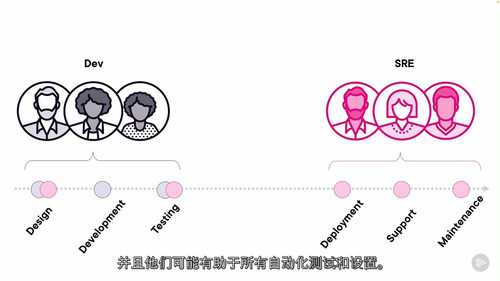
该模块首先以 “什么是 SRE” 为起点,清晰界定 SRE 的定义与核心价值 —— 它并非传统意义上的运维角色,而是通过工程化手段解决系统可靠性问题的专业领域,核心目标是在业务快速迭代与系统稳定运行之间找到平衡。随后,课程通过 “软件交付问题解决” 视频,结合实际案例拆解 SRE 在软件发布环节的介入方式,比如如何通过自动化工具排查交付故障、优化发布流程,减少因交付问题导致的系统不稳定风险。
“SRE 的一天(第一部分)” 则以场景化视角,还原 SRE 工程师的日常工作流程:从接收系统告警、快速响应故障,到协同开发团队定位问题,展现 SRE 在实际工作中的角色定位与协作模式。为了让学习者更直观地掌握故障响应流程,模块中包含 “响应告警实战演示” 与 “缓解生产环境问题实战演示” 两个实操视频,通过模拟真实生产环境中的告警场景, step-by-step 演示 SRE 如何根据告警信息判断问题等级、调用监控数据、执行初步缓解措施,最终协同排查根源,让理论知识落地为可操作的技能。
此外,模块还重点辨析了 SRE 与两个易混淆角色的差异:“SRE 与 IT 运维(IT Ops)的区别” 明确二者核心目标的不同 ——IT 运维更侧重 “维持系统正常运行”,而 SRE 更强调 “通过工程化手段提升系统可靠性上限”;“SRE 与 DevOps 的区别” 则指出,DevOps 聚焦 “开发与运维的协同效率”,SRE 则是 DevOps 理念在 “可靠性领域” 的具体落地实践,二者相辅相成但各有侧重,帮助学习者避免角色认知混淆。
二、量化服务性能:用服务级别指标把控质量
第二模块 “用服务级别分类与跟踪性能”(Classifying and Tracking Performance with Service Levels)同样包含 7 个视频,核心是教会学习者如何用 “可量化的指标” 定义与跟踪服务质量,这是 SRE 方法论的核心环节。
模块开篇通过 “服务级别目标(SLO)介绍”,明确 SLO 的定义 —— 它是服务提供者与用户之间约定的 “服务质量期望”,比如 “系统 99.9% 的可用率”“接口响应时间低于 200ms”,并解释为何 SLO 是 SRE 工作的 “核心锚点”:没有量化的 SLO,系统可靠性就失去了评判标准,业务需求与技术实现也会缺乏对齐依据。
“SRE 的一天(第二部分)” 承接第一模块的场景,进一步展现 SRE 如何在日常工作中围绕 SLO 开展工作 —— 比如定期检查 SLO 达成情况、根据 SLO 偏差调整资源配置,让学习者看到 SLO 在实际工作中的应用场景。“理解 SLO 与错误预算” 是本模块的重点内容,课程清晰拆解 “错误预算” 的概念:它是 SLO 允许的 “服务不可用时间或错误率”(例如 99.9% 可用率对应的错误预算为 8.76 小时 / 年),并解释错误预算的核心价值 —— 它为业务迭代提供了 “安全边界”:只要错误预算未耗尽,开发团队就可放心推进新功能上线;若错误预算耗尽,则需暂停迭代、优先修复稳定性问题,这一机制有效平衡了 “业务速度” 与 “系统稳定”。
为了让学习者掌握 “如何落地 SLO”,模块包含 “复现性能问题实战演示” 与 “添加指标与追踪实战演示” 两个实操视频:前者演示如何通过模拟用户请求、复现性能瓶颈,为定义 SLO 提供数据支撑;后者则讲解如何搭建监控体系 —— 比如配置接口响应时间、错误率等关键指标(SLI,服务级别指标)的监控告警,通过链路追踪定位性能问题根源,让 SLO 的跟踪有了具体工具支撑。最后,“探索 SLI 与监控栈” 详细介绍了 SRE 常用的监控工具链逻辑(如数据采集、存储、可视化、告警触发的全流程),“为何 SLO 优于 SLA” 则对比了 SLO(内部质量目标)与 SLA(外部服务协议)的差异,强调 SLO 更能驱动团队主动提升可靠性,而非被动应对外部投诉。
三、管控风险:在错误预算内降低系统 downtime
第三模块 “管理风险与减少停机时间”(Managing Risk and Reducing Downtime)包含 5 个视频,聚焦 SRE 如何通过风险管控手段,减少系统停机时间(downtime),核心是 “在错误预算框架下开展风险决策”。
“让 SLO 与业务目标对齐” 是本模块的基础,课程指出,SLO 并非技术团队的 “自说自话”,而是必须与业务优先级挂钩 —— 例如核心交易系统的 SLO 需设定为 99.99%(每年停机不超过 52 分钟),而内部管理系统的 SLO 可适当降低至 99.9%,通过案例讲解如何根据业务重要性划分 SLO 等级,确保技术资源向核心业务倾斜。
“在错误预算内部署” 是本模块的核心实践逻辑,课程通过实际案例演示如何基于错误预算制定发布策略:比如当错误预算充足时,可采用 “蓝绿部署”“金丝雀发布” 快速推进新功能;当错误预算紧张时,则需收紧发布策略,增加灰度验证时长,甚至暂停非关键功能发布,通过这一机制将发布风险控制在可接受范围。“SRE 与应用架构” 则从架构设计层面讲解 SRE 的介入点 —— 比如如何通过 “微服务拆分”“多可用区部署”“容灾备份设计” 提升系统抗风险能力,减少单点故障导致的大规模停机,让学习者理解 “架构层面的可靠性设计” 比 “故障后的修复” 更重要。
模块中的两个实战演示视频进一步强化实操能力:“基于 SLO 的自动化测试实战演示” 讲解如何将 SLO 指标融入自动化测试流程 —— 比如在测试环境中模拟高并发场景,验证系统是否能满足 SLO 约定的响应时间,提前发现性能风险;“测试新架构实战演示” 则以 “系统架构升级” 为场景,演示 SRE 如何通过压力测试、故障注入测试(如模拟服务器宕机、网络中断),验证新架构的可靠性是否符合 SLO 要求,确保架构变更不会引入新的稳定性风险。
四、应对故障:标准化的事件管理流程
第四模块 “通过事件管理应对故障”(Handling Failure with Incident Management)包含 5 个视频,聚焦 SRE 如何科学应对已发生的故障(事件),核心是 “通过标准化流程减少故障影响范围、缩短故障恢复时间(MTTR)”。
“何时事件升级为故障” 首先明确 “事件” 与 “故障” 的界定标准 —— 并非所有系统异常都是故障,只有当异常影响到用户体验或业务连续性时,才升级为故障(如核心接口报错率超过 1%、用户无法完成支付),帮助学习者建立 “分级响应” 的意识,避免资源浪费在非关键异常上。“触发故障响应实战演示” 通过模拟 “用户支付失败” 场景,演示如何根据预设的故障等级(如 P0 级:核心业务中断;P1 级:部分用户受影响)触发对应的响应流程 —— 比如 P0 级故障需立即拉起跨团队应急会议,P1 级故障可由 SRE 团队先初步排查,让学习者掌握故障响应的启动逻辑。
“理解事件管理” 系统讲解了 SRE 事件管理的标准化流程:从 “故障发现与上报”“组建应急团队(如总指挥、技术排查、沟通协调角色分工)”“执行临时缓解措施(如流量切分、回滚版本)”“定位根本原因”“修复问题与恢复服务” 到 “故障复盘准备”,每个环节都明确职责与操作规范,确保故障应对过程有序高效,避免因混乱导致故障扩大或恢复延迟。“超越运行手册排查故障实战演示” 则针对 “非典型故障”(即运行手册中未覆盖的场景),演示如何通过日志分析、链路追踪、压力测试等手段排查问题,培养学习者的 “故障排查思维”,而非仅依赖固定流程。“高效处理故障” 则分享了 SRE 在故障处理中的实用技巧,比如 “先恢复服务再定位根源”(优先保障业务连续性)、“实时同步故障进展(避免信息差)”、“事后记录关键时间节点(为复盘做准备)”,帮助学习者提升故障处理的效率与质量。
五、复盘与改进:让故障成为提升的契机
第五模块 “通过事后复盘反思与改进实践”(Reflecting and Improving Practices with Postmortems)包含 6 个视频,核心是 “SRE 的闭环改进机制”—— 通过事后复盘(Postmortem)从故障中吸取经验,避免同类问题重复发生,同时包含课程总结内容。
“我们需要事后复盘吗” 首先解答学习者的潜在疑问:为何每个故障都需要复盘?课程指出,复盘的核心价值并非 “追责”,而是 “发现系统、流程或认知中的漏洞”—— 即使是小故障,也可能隐藏着架构设计缺陷或流程盲区,通过复盘可将 “故障成本” 转化为 “改进动力”,并通过实际案例证明复盘对降低故障复发率的显著效果。“生成与发布复盘报告” 讲解复盘报告的标准化结构:包括故障概述(时间线、影响范围)、根本原因分析(采用 “5Why”“鱼骨图” 等工具)、改进措施(明确责任人与时间节点)、经验总结,确保复盘报告具备 “可落地、可追溯” 的特点,而非流于形式。
两个 “撰写复盘报告实战演示” 视频(Part 1 与 Part 2)以 “某电商平台促销期间系统卡顿” 故障为例,完整演示复盘报告的撰写过程:从梳理故障时间线(如 “10:00 流量骤增→10:05 接口响应超时→10:15 回滚版本后恢复”),到用 “5Why” 定位根本原因(“卡顿→数据库连接池耗尽→连接池配置未随促销流量调整→未建立促销场景的资源评估流程”),再到制定改进措施(“建立促销前资源评估机制、配置数据库连接池动态扩容”),让学习者掌握复盘报告的实操撰写方法。“让复盘报告发挥价值” 则强调复盘后的 “落地跟踪”—— 如何通过定期检查改进措施的执行情况、验证改进效果,确保复盘不是 “一次性活动”,而是形成 “故障→复盘→改进→验证” 的闭环,真正实现系统可靠性的持续提升。
最后,“课程总结” 视频梳理了整个课程的核心逻辑:从 SRE 的定义与角色定位,到以 SLO 和错误预算为核心的量化管理,再到风险管控、事件管理与事后复盘的全流程实践,帮助学习者构建完整的 SRE 知识框架,同时强调 SRE 并非 “一套固定的工具或流程”,而是 “以可靠性为目标的工程化思维”,鼓励学习者在实际工作中结合业务场景灵活应用。
本课程所有视频均配备中文字幕,确保不同英语基础的学习者都能清晰理解内容;视频内容兼顾理论讲解与实战演示,既有方法论层面的深度拆解,也有可直接复用的操作流程,助力学习者从 “理解 SRE” 到 “落地 SRE”,切实提升所在团队的系统可靠性与服务质量。