资源介绍
教程)
本课程是一套聚焦大语言模型(LLM)底层原理与实战开发的系统化视频教程,共包含 48 个核心教学视频,配套完整中文字幕(srt 格式),帮助学习者从基础环境搭建到实际模型部署,逐步掌握 LLM 的构建逻辑与编程实现能力。
课程采用 “理论拆解 + 代码落地” 的双轨教学模式,内容覆盖大语言模型开发全流程,从最基础的 Python 环境配置起步,层层深入核心技术模块。在基础准备阶段,学习者将掌握文本分词、令牌 ID 转换、特殊上下文令牌添加等文本预处理关键技能,同时理解字节对编码(BPE)、滑动窗口数据采样等核心数据处理方法,为模型训练奠定基础。随后,课程详细讲解令牌嵌入创建、词位置编码等基础技术,帮助学习者建立对语言模型输入层设计的完整认知。
自注意力机制作为 LLM 的核心技术,课程通过多个专项视频进行递进式教学:从无训练权重的简单自注意力机制入门,分步拆解注意力权重计算过程,再到紧凑式自注意力 Python 类的实现,让学习者直观理解自注意力的工作原理。在此基础上,课程进一步拓展至因果注意力掩码、dropout 注意力权重掩码等优化技术,以及因果自注意力类的开发、多头注意力层堆叠与权重拆分实现,全面覆盖自注意力机制的进阶应用与工程优化。
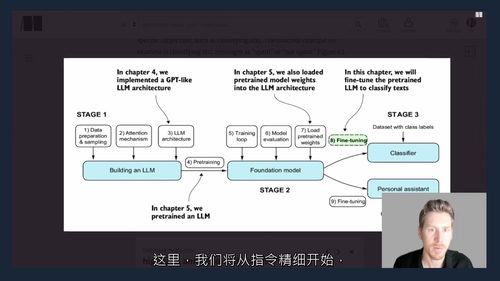
在模型架构搭建阶段,课程聚焦 Transformer 与 GPT 模型的实战开发,系统讲解层归一化、GELU 激活函数前馈网络、 shortcut 连接等关键组件的实现方法,以及注意力层与线性层在 Transformer 块中的整合逻辑。通过完整的代码演示,学习者将掌握 GPT 模型的整体编码流程,以及文本生成功能的核心实现技巧,完成从模型组件开发到完整架构搭建的跨越。
模型训练与优化部分,课程围绕文本生成损失计算(交叉熵、困惑度)、训练集与验证集损失评估、LLM 全流程训练等核心任务展开,同时深入讲解温度调节、Top-k 采样等解码策略,帮助学习者掌握控制文本生成随机性的方法,提升生成内容的质量与可控性。此外,课程还涵盖 PyTorch 框架下模型权重的加载与保存技巧,为模型的后续部署与迭代提供技术支持。
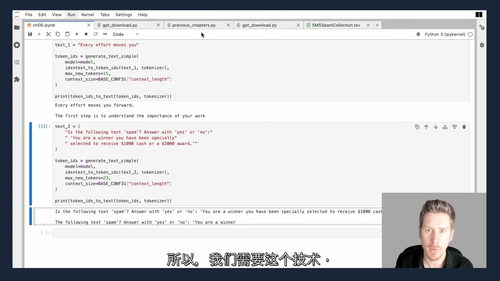
应用实战环节,课程通过数据集准备、数据加载器创建、预训练权重初始化等前置步骤,引导学习者完成模型微调全流程 —— 包括添加分类头、计算分类损失与准确率、基于有监督数据的模型微调,最终实现将 LLM 应用于垃圾信息分类等实际场景。同时,课程专门设置有监督指令微调模块,详细讲解指令数据集构建、训练批次组织、指令数据加载器开发等关键步骤,以及预训练 LLM 的加载、指令微调实现、响应提取与保存、微调后模型评估等完整流程,帮助学习者掌握提升模型指令遵循能力的核心方法。
本课程所有教学内容均基于 Python 编程语言与 PyTorch 框架展开,代码实现简洁易懂,逻辑清晰,适合具备基础 Python 编程能力与机器学习入门知识的学习者。无论是希望深入理解 LLM 底层原理的技术爱好者,还是寻求大语言模型实战开发能力的工程师,都能通过本课程系统掌握从 0 到 1 构建、训练与优化大语言模型的核心技能,为后续从事 LLM 相关研究与开发工作奠定坚实基础。课程配套的中文字幕确保学习者能够精准理解教学内容,高效吸收技术要点,提升学习效率。