
资源介绍
MLOps 实战进阶:企业级机器学习项目全流程开发与部署(中文字幕英文视频教程)
本课程是一套聚焦 MLOps(机器学习运维)领域的实战型课程,专为追求专业进阶的机器学习从业者、数据工程师及运维人员打造,通过完整的企业级项目案例,系统讲解机器学习项目从规划、数据处理到模型开发、流程管理、部署上线的全生命周期管理方法,帮助学习者掌握工业化场景下机器学习项目的标准化开发与运维能力。
课程整体分为 7 大核心模块,包含 23 个视频文件(均配备中文字幕文件),搭配大量可直接复用的代码脚本、项目配置文件及 Notebook 实战案例,形成 “理论讲解 + 代码实操 + 项目落地” 的三维学习体系,让学习者能边学边练,快速将知识转化为实际工作能力。
模块一:项目规划与入门(1 个视频)
作为课程的开篇,本模块首先明确 MLOps 项目的核心目标与价值,帮助学习者建立对机器学习全流程管理的整体认知。视频内容围绕项目规划方法论展开,涵盖需求分析、流程拆解、资源配置、进度管理等关键环节,同时介绍后续实战项目的背景与技术栈,为整个学习过程奠定基础。该模块配备 1 个中文字幕文件,确保学习者能清晰理解项目启动阶段的核心要点。
模块二:数据管理与预处理(2 个视频)
数据是机器学习项目的核心资产,本模块聚焦数据全流程管理的标准化操作。第一个视频详细讲解数据采集的原则与方法,包括多来源数据整合、数据质量校验、原始数据存储规范等内容,帮助学习者建立 “数据溯源” 与 “质量优先” 的意识;第二个视频深入数据预处理与探索性数据分析(EDA)环节,涵盖缺失值处理、异常值检测、特征工程、数据可视化等实操技巧,并配套 1 个 Jupyter Notebook 文件(2 -1_Preprocessing_&_EDA.ipynb),学习者可跟随代码逐行实践,掌握数据清洗与特征优化的核心方法。两个视频均配备中文字幕文件,关键操作步骤与代码逻辑均有清晰讲解。
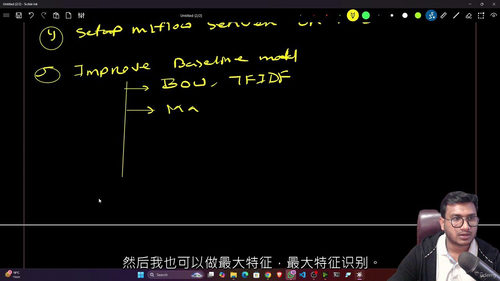
模块三:MLFlow 服务端搭建(1 个视频)
模型实验管理是 MLOps 的核心环节之一,本模块聚焦 MLFlow 工具的实战应用,重点讲解服务端的搭建流程。视频内容从环境配置、依赖安装入手,逐步演示服务端部署的完整步骤,同时介绍 MLFlow 的核心功能(如实验跟踪、参数记录、模型存储),帮助学习者建立对模型实验标准化管理的认知。模块内还包含 “MLflow-Basic-Demo-main” 示例项目文件夹,提供 argv_exp.py、example.py 等 5 个核心代码文件及依赖清单(requirements.txt),学习者可直接运行示例代码,快速上手 MLFlow 的基础操作。该模块配备 1 个中文字幕文件,复杂的部署步骤均有细致讲解,降低操作门槛。
模块四:基于 MLFlow 的基准模型开发与优化(6 个视频)
本模块是模型开发的核心实战环节,围绕 “基准模型构建 - 性能优化 - 高级调参” 的逻辑展开,通过 6 个视频逐步深入模型开发的关键技术。第一个视频讲解基准模型的构建方法,基于 MLFlow 实现模型训练过程的参数记录与实验跟踪;第二个视频引入 BOW、TFIDF 等文本特征提取技术,优化模型输入特征,提升基准模型性能;第三个视频聚焦 TFIDF 特征的参数调优(如 (1,3) ngram 设置、max_features 参数优化),讲解特征工程对模型效果的影响;第四个视频针对数据不平衡问题,介绍常用的处理策略(如采样、权重调整),并演示如何在 MLFlow 中记录不同策略的实验效果;第五个视频深入模型超参数调优,以多种经典模型为例,讲解超参数搜索方法与性能对比分析;第六个视频介绍模型集成技术(Stacking),演示如何通过多模型组合进一步提升预测精度。
该模块配套 6 个 Jupyter Notebook 文件(从 2_experiment_1_baseline_model.ipynb 到 8_stacking.ipynb),每个 Notebook 对应一个实验场景,代码注释详细,可直接复现实验过程。6 个视频均配备中文字幕文件,模型开发过程中的关键逻辑、参数选择理由及实验结果分析均有清晰解读,帮助学习者理解 “实验 - 记录 - 优化” 的迭代式模型开发思路。
模块五:基于 DVC 的机器学习全流程 pipeline 构建(6 个视频)
数据版本控制(DVC)是 MLOps 中保障数据与流程可追溯的关键工具,本模块围绕 “全流程 pipeline 开发” 展开,通过 6 个视频讲解从数据到模型的标准化流程构建。第一个视频介绍 DVC 的核心概念与价值,演示 pipeline 的整体搭建框架;第二至六个视频分别聚焦 pipeline 的五大核心组件:数据接入(Data Ingestion)、数据预处理(Data Preprocessing)、模型构建(Model Building)、模型评估(Model Evaluation)、模型注册(Model Registration),每个组件均从 “功能设计 - 代码实现 - 流程集成 - 版本控制” 四个维度展开讲解,同时演示如何与 MLFlow 联动(如模型评估结果自动同步至 MLFlow、模型注册与 MLFlow 模型库关联)。
模块内包含 “End-to-end-Youtube-Sentiment” 完整项目文件夹,涵盖项目配置文件(dvc.yaml、params.yaml)、核心代码脚本(如 data_ingestion.py、model_evaluation.py)、数据存储目录(含原始数据与处理后数据)、模型文件及日志文件等,完整还原企业级项目的目录结构与文件组织方式。6 个视频均配备中文字幕文件,复杂的 pipeline 逻辑与组件集成细节均有分步讲解,帮助学习者掌握可复用、可追溯的机器学习流程开发能力。
模块六:浏览器插件完整实现(2 个视频)
本模块聚焦机器学习模型的前端应用落地,讲解如何将训练好的模型通过 API 接口与浏览器插件结合,实现 “模型能力产品化”。第一个视频讲解 Flask API 的开发过程,包括接口设计、请求处理、模型调用、响应返回等关键环节,确保 API 的稳定性与易用性;第二个视频深入浏览器插件的开发,涵盖插件配置(manifest 文件)、前端页面设计(popup.html)、交互逻辑实现(popup.js)及插件调试方法,演示如何通过插件调用后端 API,实现模型预测结果的实时展示。
两个视频均配备中文字幕文件,前端开发与后端接口的联调细节、跨域问题处理、用户体验优化等实用技巧均有讲解,帮助学习者打通 “模型开发 - 接口封装 - 前端应用” 的链路,理解机器学习模型的产品化落地思路。
模块七:基于容器化的 CICD 部署(2 个视频)
部署上线是机器学习项目产生价值的关键一步,本模块聚焦 “容器化 + CICD” 的工业化部署方案,讲解如何实现模型与应用的自动化部署。第一个视频介绍容器化技术的核心价值,演示 Docker 镜像的构建过程(含 Dockerfile 编写、依赖打包、镜像优化),确保项目环境的一致性与可移植性;第二个视频讲解 CICD(持续集成 / 持续部署)流程的搭建,包括代码提交触发构建、自动化测试、镜像推送、服务器部署等环节,通过配置文件(如 cicd.yaml)演示如何实现部署流程的自动化,减少人工操作成本,提升部署效率与稳定性。
模块内同样包含完整的项目文件夹,提供 Dockerfile、CICD 配置文件及部署所需的各类脚本,学习者可参考配置实现自己的自动化部署流程。两个视频均配备中文字幕文件,容器化部署中的环境配置、权限管理、安全防护(如镜像安全校验、部署环境访问控制)等关键问题均有讲解,帮助学习者掌握企业级项目的安全部署方法。
课程特色
实战导向:全程以完整项目为核心,所有知识点均围绕项目需求展开,避免 “纯理论” 学习,学习者可直接复用课程中的代码与配置,快速应用到实际工作中。
技术全面:覆盖 MLOps 核心工具(MLFlow、DVC、Docker)与关键环节(数据管理、模型开发、流程构建、部署上线),形成完整的技术体系,满足工业化场景需求。
资源丰富:提供 23 个视频(含中文字幕)、12 个 Jupyter Notebook、数十个代码脚本与配置文件,资源类型多样,支持多维度学习与实践。
注重规范:强调机器学习项目的标准化与可追溯性,从数据版本、实验记录到流程配置,均遵循企业级开发规范,帮助学习者建立工业化思维。
无论是希望转型 MLOps 领域的机器学习工程师,还是需要提升项目管理能力的数据从业者,本课程都能提供系统的知识与实战经验,助力学习者在专业领域实现进阶,应对企业级机器学习项目的复杂挑战。