资源介绍
)
本教程是一套体系完整、由浅入深的 Python 数据科学全流程实战课程,全程配备标准中文字幕,助力学习者无障碍掌握数据科学核心技能,课程共包含44 个高清教学视频,覆盖从零基础入门到进阶实战的全维度知识,是想要系统学习数据科学、搭建完整知识体系的优质学习资源。
课程以 Python 为核心工具,围绕数据科学实际应用场景展开教学,摒弃冗余理论,侧重实操与落地,无论你是零基础的编程新手、想要转行数据领域的职场人,还是需要提升数据处理与分析能力的在职人员,都能通过这套课程稳步搭建知识框架,掌握数据科学必备的编程、处理、分析、可视化与建模能力。
课程第一部分聚焦数据科学与 Python 入门,先清晰解读数据科学的核心定义与应用价值,让学习者明确学习方向;再讲解 Python 成为数据科学主流工具的核心优势,建立正确的学习认知;随后教学 Jupyter Notebooks 这一数据科学常用开发工具的使用方法,最后通过编写首个 Python 脚本完成入门实战,帮助零基础学习者快速上手,消除编程畏惧心理。
第二部分夯实 Python 数据科学基础语法,系统讲解变量、数据类型与运算符,掌握编程基础要素;学习条件判断、循环等流程控制逻辑,实现代码的灵活运行;深入理解函数与作用域,编写模块化、可复用的代码;掌握模块与包的使用方法,拓展 Python 功能;学习异常处理与断言编写,提升代码的稳定性与健壮性,为后续数据处理与分析打下坚实的编程根基。
第三部分专注 Pandas 数据处理核心技能,作为数据科学的核心工具,课程先讲解 Pandas 中 Series 和 DataFrames 两大核心数据结构,再教学 CSV、Excel、JSON 等主流数据格式的读写操作,解决数据获取与存储问题;重点讲解数据清洗与预处理、缺失值和重复值处理,搞定数据预处理这一数据科学的关键环节;还涵盖数据转换与特征工程、数据分组排序与聚合等实用技能,让学习者具备独立处理各类业务数据的能力。
第四部分学习 NumPy 数值计算,对比数组与列表的差异,理解 NumPy 的高效性;掌握数组的创建、索引与切片操作,灵活操作数据;学习 NumPy 数学运算、广播机制与向量化计算,大幅提升数值运算效率;了解数据科学场景中常用的 NumPy 函数,为后续数据分析与建模提供高效的数值计算支持。
第五部分聚焦数据可视化技能,先讲解数据可视化的核心意义与应用场景,再教学 Matplotlib 基础绘图方法,掌握柱状图、折线图、散点图等基础图表;学习图表颜色、标签、图例等自定义设置,让可视化结果更清晰美观;进阶学习热力图、配对图、小提琴图等高级图表,还可选择学习交互式可视化,让数据呈现更直观、更具交互性,轻松通过图表传递数据规律。
第六部分系统学习探索性数据分析(EDA),明确 EDA 的核心价值,学习识别数据中的模式、异常值与趋势,掌握数据洞察的基础方法;学习描述统计、相关性分析等核心分析手段,挖掘数据内在联系;还可选择学习 Pandas Profiling、Sweetviz 自动化分析工具,提升数据分析效率,实现从数据到结论的高效转化。
第七部分补充数据科学必备统计学知识,讲解均值、中位数、众数、方差、标准差等基础统计量,理解数据的分布特征;学习概率核心概念,建立统计思维;掌握假设检验、置信区间等统计推断方法,最后搭建线性回归的核心直觉,为机器学习学习筑牢理论基础。
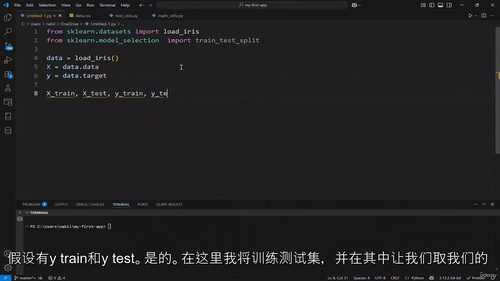
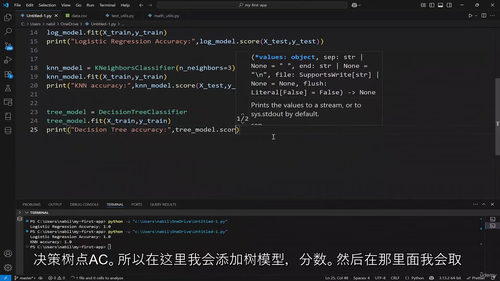
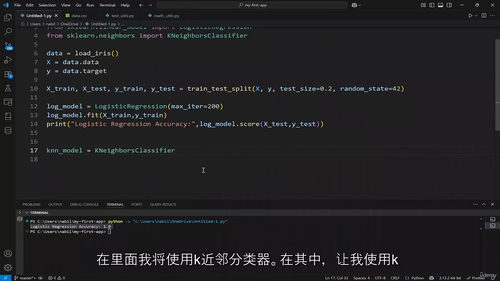
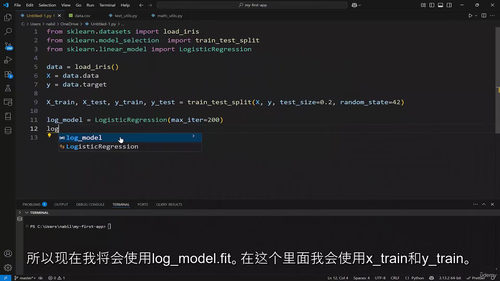
第八部分进入机器学习实战,基于 Scikit Learn 框架展开教学,先明确机器学习的定义与分类,区分监督学习与无监督学习;梳理机器学习完整工作流程,掌握数据准备、模型训练、评估与调优的全步骤;实战学习线性、岭回归、Lasso 等回归算法,逻辑回归、K 近邻、决策树等分类算法,以及 K 均值聚类算法,掌握机器学习主流模型的应用方法。
第九部分为进阶拓展内容,属于可选学习模块,涵盖时间序列分析入门,满足时序数据处理需求;讲解 TensorFlow、Keras 深度学习基础,入门人工智能核心领域;还介绍 PySpark 大数据处理基础,拓展大数据场景下的数据处理能力,帮助学有余力的学习者进一步提升技术广度。
整套课程逻辑清晰、循序渐进,从基础编程到数据处理,从分析可视化到统计学、机器学习,再到进阶拓展,完整覆盖数据科学必备技能栈。配套中文字幕彻底消除语言学习障碍,44 个视频课程聚焦实战,学完即可具备独立完成数据处理、数据分析、机器学习建模的核心能力,是通往数据科学领域的系统化学习指南。