资源介绍
本课程是一套全面系统的网络爬虫实战教程,共包含 53 个视频模块,配套完整中文字幕(srt 格式)及全部实战代码文件,旨在帮助学习者从基础到进阶掌握网络爬虫的核心技术、合规应用及实战技巧,同时强化网络安全防护意识,提升数据获取的合法性与安全性。
课程开篇首先明确网络爬虫的法律边界与合规要求,清晰界定爬虫行为与黑客攻击的本质区别,引导学习者在合法合规的框架内开展数据获取工作。同时,课程强调网络安全防护的重要性,通过解析各类防护机制,帮助学习者理解如何在爬虫操作中规避风险,既保障自身操作的合规性,也提升对网络安全的认知与防御能力。
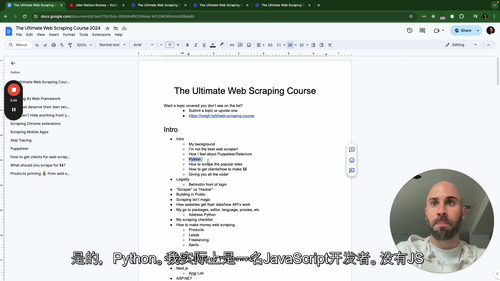
在技术基础部分,课程详细讲解了网络爬虫的核心原理,包括网站数据的来源与传输机制、数据定位与提取方法,以及课程将用到的核心工具与服务的配置和使用。学习者将掌握一套通用的爬虫工作流程,学会快速定位目标网站的数据接口、分析数据加载逻辑,为后续各类场景的实战操作奠定基础。
实战模块是本课程的核心亮点,覆盖了当前主流的各类网站与应用场景,包括不同技术架构的网站(如 HTML 静态网站、Next.js、ASP.NET、Java 开发的动态网站等)、主流平台(地图服务、职场社交平台、电商平台、社交媒体、房产信息平台、短视频平台等),以及移动应用的数据爬取。每个实战案例均提供完整的代码实现(含 JavaScript 等相关语言的源码文件),从环境搭建、代码编写、调试优化到数据存储,全程手把手教学,帮助学习者解决实际操作中遇到的各类问题,如反爬机制突破、验证码识别、分页数据获取、动态内容爬取等。
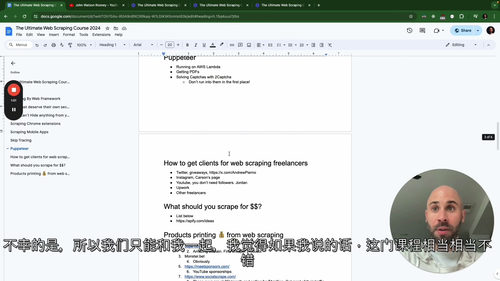
针对爬虫过程中常见的技术难点,课程专门设置了专项解决方案模块,包括代理服务器的使用、CloudFlare 等防护机制的突破技巧、身份验证令牌的安全处理、基于 Puppeteer 的无头浏览器应用(如动态页面渲染、视频获取、验证码解决等)、数据库高效管理等内容。同时,课程还讲解了并发爬取的实现与优化,帮助学习者提升数据获取效率,应对大规模数据采集需求。
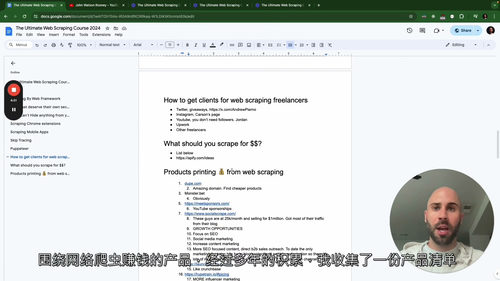
除技术教学外,课程还包含实用的商业应用模块,分享如何将网络爬虫技术转化为实际价值,包括爬虫业务的客户开发、服务定价策略、适合爬虫获取的高价值数据类型等,为有创业或副业需求的学习者提供清晰的方向指引。
配套的代码文件夹包含了所有实战案例的完整源码,涵盖各类平台的爬取脚本、工具类函数、配置文件及数据样本,学习者可直接下载使用、二次开发,大大降低实践门槛。同时,课程提供的中文字幕确保了学习过程的流畅性,帮助学习者精准理解技术细节与操作要点。
无论你是零基础的技术爱好者,希望入门网络爬虫领域;还是有一定编程基础,想要提升爬虫实战能力、拓展数据获取场景的开发者;亦或是需要通过爬虫技术解决工作中的数据采集需求的职场人,本课程都能为你提供系统、全面、实用的指导。通过本课程的学习,你将不仅掌握各类场景下的爬虫技术,更能建立合规、安全的操作意识,真正做到技术服务于需求,在合法合规的前提下高效获取有价值的数据。