


资源介绍
视频数量:43个
总时长:9小时38分
课程介绍:
Databricks数据工程师全栈课程
你有没有遇到过这种情况:老板让你从一堆乱七八糟的数据里找出业务问题的答案,结果你对着几个GB的Excel文件发呆,不知道从哪里下手。或者你是刚入行的数据分析师,花了大量时间清洗数据,却发现自己80%的时间都在做重复劳动,真正有价值的分析工作反而没时间做。
这种情况在数据行业太常见了。问题的根源往往不在分析能力,而在于底层的数据架构和处理逻辑。
数据工程,简而言之,就是解决数据从产生到能够被有效使用这个过程中的各种技术问题。你可以把数据工程想象成自来水厂的工作:原始数据就像未经处理的原水,浑浊不堪、杂质众多,数据工程师的任务就是建设管道、过滤净化,让干净的水(可用的数据)流向千家万户。没有这套基础设施,再好的分析师也只能对着原水叹气。
Databricks就是目前数据工程领域最热门的平台之一。它把Apache Spark的强大能力包装成了一个云原生的协作环境,Netflix、麦当劳、壳牌石油这些大公司都在用它处理每天数以PB计的数据。这门课就是围绕Databricks展开的系统性学习,从最基础的概念讲起,一直覆盖到生产环境中真正会用到的各种高级技巧。
课程内容非常扎实,一共十二个模块,涵盖了近十个小时的干货。我们先从现代数据工程的整体框架开始,了解数据架构是怎么从最早的单体数据库演进到今天这种分布式 lakehouse 模式的。之所以要先讲这些,是因为很多人在实际工作中只接触一小块内容,容易陷入技术细节而看不到全貌。知道了数据工程解决的是什么问题,才能更好地理解后面学的每个工具和概念。
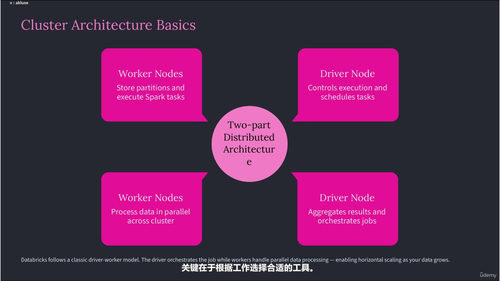
接下来就是Databricks本身的上手操作。工作区怎么导航、集群怎么创建和管理、notebook怎么用、DBFS文件系统是怎么回事,这些内容会带着你一步步熟悉整个界面。Databricks和其他开发环境有些不同,它的设计初衷就是让数据工程师和数据科学家能够在一个平台上协作完成从数据处理到模型训练的完整流程,所以提前熟悉这些基础设施会省去很多后续的麻烦。
有了基本操作能力之后,我们开始深入Apache Spark的核心原理。这部分绝对不是蜻蜓点水式的概念介绍,而是会讲透DataFrames这种Spark最核心的数据抽象、分布式架构是怎么工作的、为什么Spark要采用惰性求值这种设计理念、Spark SQL怎么用。DataFrames相当于整个Spark世界的通用语言,你写的每一条处理逻辑最终都会转换成对DataFrames的操作,搞清楚它的运作机制,后面的所有内容学起来都会顺畅很多。
Delta Lake是Databricks自家出品的另一个核心组件,也是lakehouse架构能够落地的关键技术。这部分会讲清楚Delta Lake解决了什么问题、schema怎么管理、数据版本怎么追踪、时间旅行功能怎么用来做审计和回滚、数据的增删改怎么操作。这些能力在生产环境中非常重要,比如说数据出问题了想回退到某个历史版本,或者想查看某个时间段的数据状态,Delta Lake直接就支持这些功能。
然后就是整个课程的核心设计理念 medallion架构,也就是大家常说的青铜、白银、黄金三层架构。青铜层存放原始的、未经处理的数据,保持数据原貌;白银层对数据进行清洗、标准化和质量检查;黄金层则是面向业务场景的聚合数据,可以直接用于分析和报表。这个架构现在已经成了数据工程的行业标准,Databricks本身的很多功能都是围绕它设计的。我们会详细讲解每一层的设计原则和具体实现方式,以及如何在数据流转过程中保持数据质量。
批处理和流处理是数据管道的两种基本模式。批处理适合那些对实时性要求不那么高的场景,比如每天跑一次的数据报表;流处理则用于需要实时响应的场景,比如实时推荐、异常检测。这门课会同时覆盖这两种模式,教你用Structured Streaming构建流处理管道、用Auto Loader自动摄取文件、处理乱序数据和迟到数据的技术细节。实际工作中,很多场景需要两种模式配合使用,所以这两块知识都得掌握。
进阶的内容还包括复杂的数据转换技巧,比如多表join、窗口函数的运用、数据去重的方法、处理缓慢变化维度的策略。这些属于数据工程师的看家本领,面试中经常会被问到,实际工作中也是每天都在用。特别说下缓慢变化维度,这是数据仓库领域的一个经典问题,处理不好会导致历史数据分析出现偏差甚至错误。
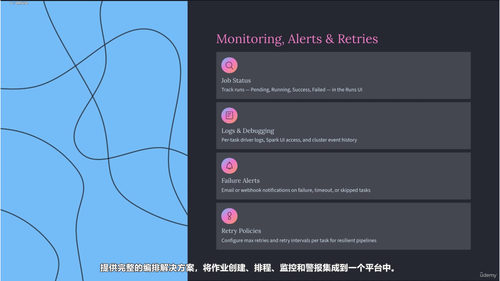
工作流编排部分会教你用Databricks自家的Workflows功能来编排和管理数据管道,包括怎么设置定时调度、怎么进行参数化、怎么让多个任务串联执行形成完整的自动化流程。没有编排工具的话,数据管道就只是一些散落的脚本,有了编排工具才能真正实现自动化、可靠性、可监控的生产级数据处理。
性能优化和数据治理也是生产环境必须考虑的。优化部分会讲分区策略、缓存机制、查询优化和成本控制,这些技能直接关系到你的 pipeline 跑得快不快、花多少钱。治理部分会覆盖Unity Catalog统一目录、权限控制和数据血缘追踪,这些在大企业里是数据合规和安全的必要保障。
最后,数据服务层会教你如何创建黄金表供下游使用、配置SQL端点、以及如何和Power BI这类BI工具对接。数据工程最终的目的是让数据被用起来,如果数据处理完了却没人能用,那前面的一切努力都白费了。
学完这门课,你能独立在Databricks上构建完整的数据管道,从原始数据摄入到最终的业务报表输出。同时你也掌握了现代数据工程的核心方法论,理解了为什么lakehouse架构能流行、medallion架构怎么落地实施。更重要的是,你具备了处理生产级数据问题的能力,知道如何保证数据质量、如何优化性能、如何做好权限管理。
如果你是刚毕业或者想转行的计算机相关专业的学生,这门课能帮你快速建立数据工程的知识体系,面试时有东西可讲。如果你是数据分析师或者BI开发,想扩展到数据工程方向,这也是一个很好的起点。如果你在传统企业里做数据仓库相关工作,想了解云原生和lakehouse这些新技术,这门课会告诉你迁移过程中需要注意什么、怎么实现平滑过渡。总的来说,只要你的工作中会接触到数据处理和管道开发,这门课都会有实际帮助。