
资源介绍
视频数量:60个
总时长:8小时34分
课程介绍:
Python机器学习与数据科学实战
你有没有想过,为什么购物网站总能精准推荐你想要的商品?为什么手机能准确识别你的语音指令?为什么银行能提前发现可能的欺诈行为?这些功能的背后,都站着一个共同的技术:机器学习。它已经不是实验室里的概念,而是正在改变我们生活和工作方式的核心能力。
这门课程用8个半小时、60个视频,带你从零开始掌握机器学习的核心内容。不是那种看完就忘的理论堆砌,而是每讲一个算法,就用Python把它写出来跑通。
先从最基础的东西说起。机器学习到底是什么?课程开篇就回答这个问题,帮你理清那些容易被混淆的术语。你会明白为什么1959年塞缪尔教授在IBM开发的跳棋程序被认为是机器学习的里程碑,为什么这个领域在2000年代才真正发展成熟。搞清楚这些背景知识,后面的学习会顺畅很多。
动手之前,环境要搭好。课程专门花了几个视频讲Anaconda的安装,Windows、Mac、Linux三个系统都有覆盖。Jupyter Notebook和Google Colab这两个常用的编程环境也会介绍清楚。不用担心自己用的是苹果还是微软的电脑,跟着视频操作就能把环境搞定。
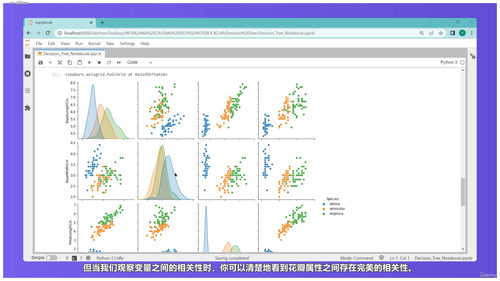
正式学习从评估指标开始。这听起来像是基础内容,但非常重要。你得先知道怎么衡量一个模型是好是坏,才能知道接下来该往哪个方向优化。课程会讲清楚分类和回归这两种不同问题的区别,分类是判断苹果还是番茄,回归是预测房价走势,两种问题用的评估方法完全不同。准确率、召回率、F1分数这些分类问题的指标,RMSE、MSE这些回归问题的指标,都会通过代码演示一遍。
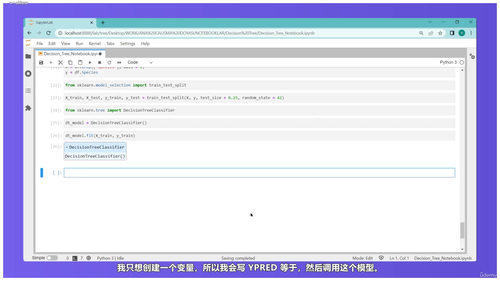
监督学习是机器学习里最核心的部分,课程花了大量篇幅来讲。从最简单的线性回归开始,什么是一元线性回归,什么是多元线性回归,最小二乘法是怎么工作的,梯度下降又是怎么回事,这些基础概念都会讲透。然后用Python把这些理论变成可运行的代码,从数据读取到模型训练再到结果预测,完整走一遍流程。
偏差方差权衡是很多人学习时会遇到的理解难点,课程专门用一节来讲。这个概念直接关系到你怎么让模型既不会欠拟合也不会过拟合,理解透了才能真正做好模型优化。
逻辑回归听起来带个“回归”二字,其实是用来解决分类问题的。比如判断一封邮件是不是垃圾短信,判断一个用户会不会流失,这类二分类问题用它最合适。课程会从原理讲起,让你理解它和线性回归的区别,然后用Python实现从简单到复杂的三分类问题。
K折交叉验证是保证模型稳定性的重要手段。你训练出来的模型到底靠不靠谱,不能只跑一次数据就下结论。K折交叉验证会把数据分成K份,轮流用其中一份做测试、其他份做训练,反复验证模型的泛化能力。这个方法在实际工作中用得非常多。
K近邻算法是最直观的分类算法之一。简单来说就是“物以类聚,人以群分”——一个新来的数据点属于哪个类别,取决于离它最近的K个邻居是什么类别。课程会讲清楚K值怎么选,距离怎么算,然后用代码实现完整的分类流程。
到这里你可能已经发现了,机器学习很大程度上就是调参的艺术。超参数优化这一节会教你GridSearch和RandomSearch两种调参方法,让你的模型从“能用”变成“好用”。
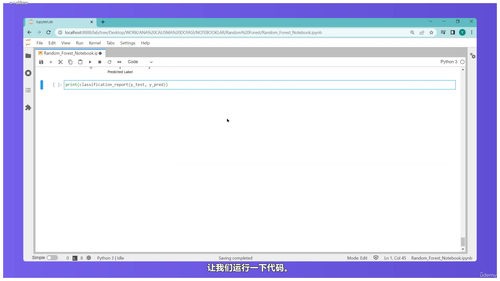
从决策树开始,课程进入了更复杂的算法领域。决策树是怎么根据特征一层层做判断的,信息增益、基尼系数这些概念是什么意思,都会讲清楚。但一棵决策树容易出现过拟合的问题,所以紧接着就讲随机森林——多棵决策树组合起来,投票决定最终结果,效果往往比单棵树好很多。
支持向量机是另一个强大的分类算法。它的核心思想是找到一个最优的超平面,把不同类别的数据点尽可能清晰地分开。课程会从几何角度解释这个原理,然后教你怎么用Python处理线性可分和不可分的情况。对于线性不可分的数据,核函数怎么选,参数怎么调,这些实战中的关键问题都会讲到。
前面讲的都是监督学习,有标签的数据才能训练模型。但现实中大量数据是没有标签的,这时候就要靠无监督学习了。
无监督学习这部分先讲了整体思路,然后重点讲了K均值聚类和层次聚类。K均值聚类是把数据自动分成K个簇,每个簇内部的相似度尽可能高,簇与簇之间的差异尽可能大。课程会讲清楚K值怎么确定,质心怎么更新,迭代什么时候停止。层次聚类则不需要预先指定K值,它会构建一个树状图,展示数据之间的层级关系。
主成分分析是处理高维数据的利器。当你的数据有几十甚至上百个特征时,全部用来训练模型既费时又容易出问题。主成分分析可以把这些特征压缩成几个主要成分,保留大部分信息的同时大大降低计算复杂度。这在图像处理、特征降维等场景用得非常多。
最后一章讲推荐系统,这是机器学习在商业领域最成功的应用之一。淘宝、抖音、Netflix这些平台的核心功能都依赖推荐算法。课程会讲清楚基于内容的推荐和协同过滤推荐的区别,让你理解为什么这些平台总能猜中你的喜好。
整个课程学下来,你会掌握机器学习从数据处理到模型训练的完整流程。线性回归、逻辑回归、K近邻、决策树、随机森林、支持向量机这些主流算法都有覆盖,而且每个算法都是先讲原理再给代码,保证你不仅知道怎么用,更知道为什么这样用。
如果你正在考虑转行做数据相关的工作,或者在工作中需要用到数据分析但还没有系统学习过,这门课可以作为你的入门路径。课程内容比较完整,从基础概念到主流算法都有涉及,学完之后再做项目就不至于无从下手了。当然,如果你是已经有一定基础的学生或者在职人员,想梳理一下知识体系,这门课也能帮你查漏补缺。
学完这门课,你能独立完成从数据探索到模型构建的全流程,也能看懂和复现常见的机器学习项目。机器学习的世界很大,这门课帮你迈出第一步,剩下的路还长,但基础打好了,后面的学习会顺畅很多。